①分析に必要なライブラリをインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
import seaborn as sns
sns.set()
②csvデータを読み込み
date = pd.read_csv("フルパス入力")
date
データフレームをフルで表示したい場合↓
pd.set_option ('display.max_rows', 行数指定)
pd.set_option ('display.max_columns', 列数指定)
③要約統計量を取得
date.describe ( )
各列ごとに平均や標準偏差、最大値、最小値、最頻値などの要約統計量を取得できる。
(例:値段と床面積)
| price | size | |
|---|---|---|
| count | 100.000000 | 100.000000 |
| mean | 292289.470160 | 853.024200 |
| std | 77051.727525 | 297.941951 |
| min | 154282.128000 | 479.750000 |
| 25% | 234280.148000 | 643.330000 |
| 50% | 280590.716000 | 696.405000 |
| 75% | 335723.696000 | 1029.322500 |
| max | 500681.128000 | 1842.510000 |
count: 要素の個数mean: 算術平均std: 標準偏差min: 最小値max: 最大値50%: 中央値(median)25%,75%: 1/4分位数、3/4分位数
④散布図を作成
従属変数と独立変数を定義する
従属: y = date["Price"]
独立: x1 = date["Size"]
散布図を表示
plt.scatter(x1,y)
plt.xlabel('Size',fontsize=20)
plt.ylabel('Price',fontsize=20)
plt.show()
↓出力結果

plt.scatter( )の引数の種類
| x, y | グラフに出力するデータ |
|---|---|
| s | サイズ (デフォルト値: 20) |
| c | 色、または、連続した色の値 |
| marker | マーカーの形 (デフォルト値: ‘o’= 円) |
| cmap | カラーマップ。c が float 型の場合のみ利用可能です。 |
| norm | c を float 型の配列を指定した場合のみ有効。正規化を行う場合の Normalize インスタンスを指定。 |
| vmin, vmax | 正規化時の最大、最小値。 指定しない場合、データの最大・最小値となります。norm にインスタンスを指定した場合、vmin, vmax の指定は無視されます。 |
| alpha | 透明度。0(透明)~1(不透明)の間の数値を指定。 |
| linewidths | 線の太さ。 |
| edgecolors | 線の色。 |
⑤回帰の実行(最小二乗法)
x = sm.add_constant(x1) //statmodelでの変数追加
results = sm.OLS(y,x).fit() //最小二乗回帰式の計算結果が代入
//fit( )は特定のモデルにおいて一番適合した結果を得る
results.summary() //結果を表示
↓出力結果
| Dep. Variable: | price | R-squared: | 0.745 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.742 |
| Method: | Least Squares | F-statistic: | 285.9 |
| Date: | Fri, 10 Dec 2021 | Prob (F-statistic): | 8.13e-31 |
| Time: | 02:08:09 | Log-Likelihood: | -1198.3 |
| No. Observations: | 100 | AIC: | 2401. |
| Df Residuals: | 98 | BIC: | 2406. |
| Df Model: | 1 | ||
| Covariance Type: | nonrobust |
OLS(最小二乗):残差の合計が最小になるような直線を決める
=全てのデータに対して最も近くなるような直線を引く
R²(決定係数):1に近い程、回帰のばらつきについて説明可能
F値:F検定に使う数値、0に近いほどそのモデルは有意ではない
(係数に関する表)
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | 1.019e+05 | 1.19e+04 | 8.550 | 0.000 | 7.83e+04 | 1.26e+05 |
| size | 223.1787 | 13.199 | 16.909 | 0.000 | 196.986 | 249.371 |
左2行は切片で回帰式の a(1019)とb(223.1787)に当たる
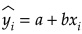 y^(ハット) = 223.1787 + 101900x₁
y^(ハット) = 223.1787 + 101900x₁
std(SSE):標準誤差(ばらつき)が小さいほど正しく予測がされている良い回帰
(検定などに使える表)
| Omnibus: | 6.262 | Durbin-Watson: | 2.267 |
|---|---|---|---|
| Prob(Omnibus): | 0.044 | Jarque-Bera (JB): | 2.938 |
| Skew: | 0.117 | Prob(JB): | 0.230 |
| Kurtosis: | 2.194 | Cond. No. | 2.75e+03 |
回帰直線を散布図の上に表示する
plt.scatter(x1,y)
yhat = x1*223.1787 + 101900
fig = plt.plot(x1, yhat, lw=4, c="orange", label="regression line" )
plt.xlabel('Size', fontsize = 20)
plt.ylabel('Price', fontsize = 20)
plt.show()
↓出力結果

補足
最小二乗法が求めている値とは、残差の二乗の合計の値を最小にしたもの。